codebase-memory-mcp
Code intelligence for AI agents: indexes any repo into a knowledge graph in milliseconds, with sub-millisecond structural queries.
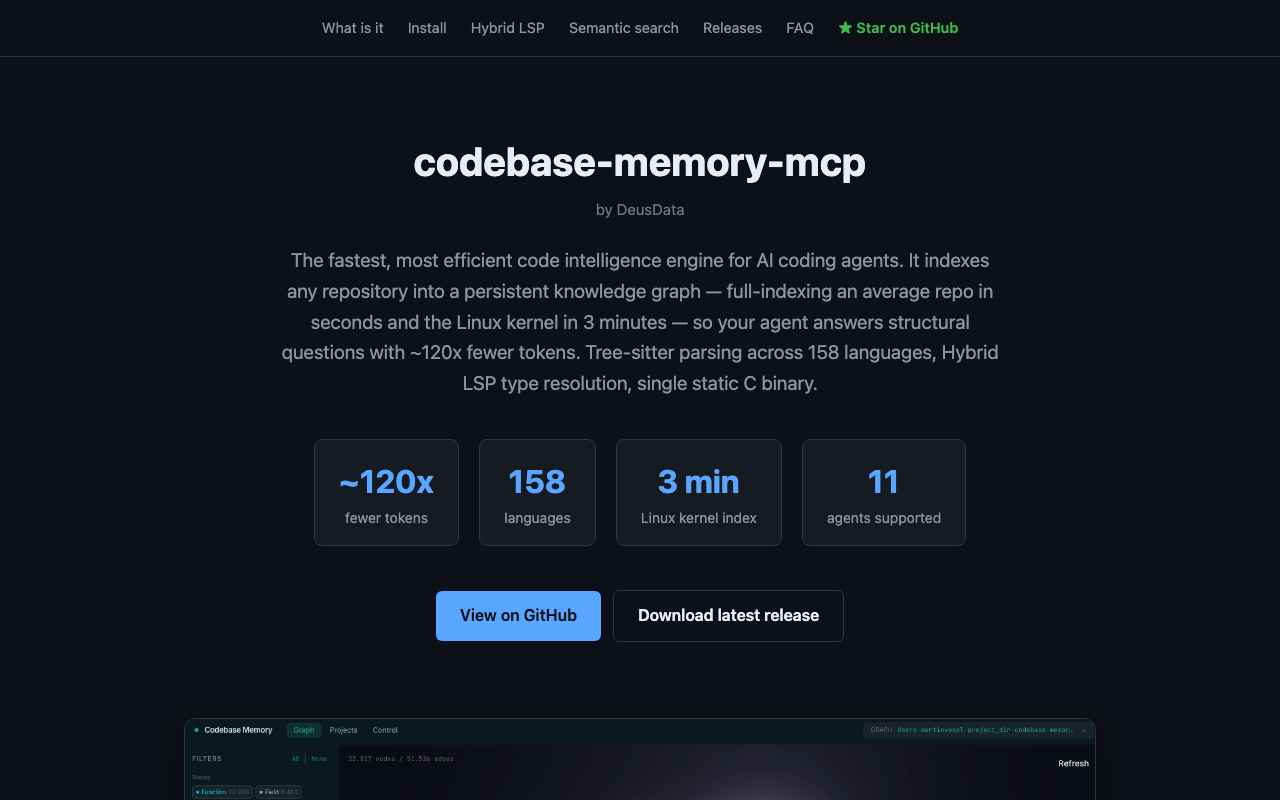
codebase-memory-mcp is a code intelligence engine built for AI coding agents. It full-indexes an average repository in milliseconds and the Linux kernel (28M lines across 75K files) in about three minutes, then answers structural queries in under a millisecond.
Parsing runs through tree-sitter across 158 languages, with a Hybrid LSP layer adding semantic type resolution for Python, TypeScript, Go, C, C++, Java, Kotlin and Rust. The result is a persistent knowledge graph of functions, classes, call chains, HTTP routes and cross-service links, exposed through 14 MCP tools.
It ships as a single static binary for macOS, Linux and Windows with zero dependencies, and plugs into eleven coding agents including Claude Code, Cursor and Codex.
7 Reviews
Log in to leave a review.
I went in skeptical, because every tool here promises millisecond queries and fewer tokens, and most of them assume a small repo. I threw a large internal project at it, north of two million lines, and the index held together. Queries stayed fast, and the type resolution was accurate enough that I trusted the call chains it returned.
It is not magic. The semantic layer covers nine languages well and the rest fall back to structural parsing, so mixed-language repos get uneven depth. Worth knowing before you lean on it. Even so, this is the first code-intelligence server I have left running instead of uninstalling after a day. For large codebases it earns its place.
I have been bolting retrieval hacks onto my coding agent for months, and most of them trade accuracy for token bloat. This is the first one that did the opposite. I indexed a 400k-line codebase, wired the MCP server into Claude Code, and the agent stopped grepping at random. It started asking for the call graph and getting answers in one round trip.
The token savings are not marketing. On a refactor that used to balloon the context window, the agent pulled the three functions it needed and left the rest on disk. Sub-millisecond queries mean no pause while it thinks. The knowledge graph view also helps me when I am trying to learn an unfamiliar service.
What sold me was how little ceremony it needed. Download the binary, run the install, restart the agent. No external database, nothing leaving my machine. If you run agents against a large repo and you are tired of watching them rediscover the structure every session, try this.
Pointed it at our monorepo and the index finished before I had read the install notes. Call-chain queries come back with no lag, which is what matters when an agent is mid-task. Tree-sitter coverage held on our Rust and Go services. Single-binary install, no Docker to babysit. Solid.
Download, run install, done. I timed the whole setup at under two minutes including reading the one paragraph I actually needed. The docs explain the fourteen MCP tools without making me read a thesis first, and the examples paste straight in. Onboarding this smooth is rare for a systems tool. New people on my team were querying the graph the same afternoon.
Indexed our 1.2 million line monorepo in under four seconds, which I did not believe until I watched it happen twice. The knowledge graph actually understands call chains across services, so my agent stops inventing function signatures that never existed. Single binary, no daemon to babysit. This is the first code intelligence tool I have left switched on after the demo.
I read through how the graph is persisted before trusting it, and the SQLite backing is tidy and easy to reason about. Cross-service links resolved correctly on a codebase that uses three transport layers, which surprised me. It does what it claims without ceremony. My one open question: how does reindexing behave on a repo with very heavy churn between commits?
The benchmark numbers made me suspicious, so I ran it against the worst repository we own: a decade of C with generated code and three build systems fighting each other. It held up. Full index in a few minutes, queries back in well under a millisecond, and memory stayed flat enough that I would run it on a build agent without flinching.
What sold me was not the speed though. It was that the graph stayed correct after I rewrote a hot module and reindexed. Stale results are the usual failure mode for this kind of tool and I could not get it to lie to me.
My one reservation is the Hybrid LSP coverage. It is excellent for the listed languages, but our older Objective-C falls back to plain tree-sitter and you can feel the difference in type resolution. For anything modern, this is comfortably the fastest correct option I have tried.